There were many lessons that worth to be remembered from the adventures of building the deployment and release management flow. Honored to spend my time working with people who were really really good at guarding production. Hint for readers prior continue: Not going to talk about tools, as through the journey I found there were other essentials that we need to enable prior talking about that. So, below are glimpse of what we went through in designing and iteratively improving the process.

First Thing First. Enable visibility of what being deployed include their potential impacts to relevant stakeholders rather aiming for aggressive improvement of lead time to changes. During early initiation of release & deployment management, we did realize that we didn’t have any visibility at all on what being deployed, and potential caused to existing systems. No service documentations about service behaviors, error mapping, dependencies, and what to validate after deployments outside of the specific changes. Complain from users occasionally occurred on next day after activities executed. We finally decide to centralize control of pre-execution checked and confirm (manually through following up service owner) what use cases impacted by the service. Notification also sent after every deployment done covering below information:
- What service being deployed
- Potential impact and what use case might be affected
- What changes included on the deployment (in non-technical communication that can be understand by business & operations entities)
- Deployment completion time
- Issues identified post deployment (if any and only applicable if we found issues that occur intermittent hence, we didn’t perform immediate rollback after deployment as we’d like to observe error rate)
The notification sent out at the end of day in daily basis to:
- Engineering team
- Product team
- Customer Services team (as they will be first gatekeeper in receiving user inquiries)
- Leadership team (Engineering, Product, and CS)
Create Basic and Minimum Requirements to Operate. Our initial deployment checklist was very simple at the beginning, only covering below:
- Proof of item has passed functional test by QA
- How to deploy
- What config that needs to be updated
Avoid ‘Panic’ Release by Defining What’s Urgent and What’s Not. Met many stakeholders that often-triggered panic release (just release and deploy after every complains/raised issue identified in production). As our deployments were still require downtime during execution, this is dangerous game to just deploy without considering the urgency versus operational/risk potential. Illustration: In the case where there are complains of intermittent blocker issues occurred to only 30 users, will you do a hotfix release on high traffic period in the user service (that consumed by millions of users)? It’s not recommended, despite of course this is arguable, some will stay stuff like this is potential reputational damage if users perform hard complain. So, we defined hotfix category as below:
- Blocker for significant amount of users
- Security findings (SQL injections, brute force, etc.)
- Functional flaw that caused to fraudulent activities
- Financial loss (this is different with revenue loss, most of revenue acquisition can be planned hence am tend to not agree to put that as hotfix category)
- Regulatory breach. If due to the findings it will cause the company to breach any local or international regulations/laws
Other than defined categories, we would require approval by at least VP level to go ahead to ensure that we made decision where operational risk will be beaten by business potential gain.
Iteratively add requirements, checklists, and other operational needs based on pain points and incidents. As provided on previous part, our deployment checklist was quite simple and minimum, during deliveries, we did observe several pain points and inefficiency due to several variables not embedded on pre-execution check.
- Service owners that missed out to put execution required in Database
- Dependencies to other entities that not yet evaluated
- Not sure on what to test post deployment in order to make decision go/rollback
- Additional infra support not yet ready or not yet requested
- Rollback guidelines were not clear
- When issues found after deployment, we could stay up till morning to troubleshoot and investigate.
So, we modified our standard checklist of deployment existing services into:
- Proof of item has passed functional test by QA or Security (especially for newly created service that require Security Test)
- QA, System Analyst and Service Owner name to confirm infra check prior execution.
- Deployment and Config Update (if any) Steps
- Rollback Steps
- Deployment Execution Time (what time deployment can start)
- Deployment Timebox (explanation will be provided below)
- Require support in Database side: Yes/No
- Require action in Database (service owner to provide script)
Additionally, to ensure we can decide efficiently and not investing unlimited time in troubleshooting error, we implement :
Design Decision Making Foundation, through
- Initiation of Standard Post Deployment Test for each service that frequently deployed so there will be no question asked why a certain change must be retained or rollback. We considered various variables from critical main use cases and high impact features/functional to users. This way, if there was any concern from Product or Business, they simply could request their main use case to be registered on our standard post deployment test, decision making will be easier as well for people who stand by on deployments, no need to wait for increment of error rate, we can validate the functional and make immediate decision to retain or rollback.
- If the changes made it to pass all the standardized functional test we will declare to retain changes and confirm to Monitoring team for performance observation, should there any behavior change (increment of error rate align with traffic increment, SRE or Monitoring team also have the same authority as Release Manager to perform and call for Rollback)
- What happen if there was an error that not huge enough to call for rollback? This happens and should the error was not providing high risk for users, most likely will retain the changes while observing further, but notification will be made to Customer Service team on this error so they will be getting ready should there be any complain from users.
Limitation of Decision-Making Period to Enable Efficient Process
Longer time in making decision cost longer bad impact for our users should something goes wrong during deployment. Hence, we decide timebox post deployment to make decision. This period needs to cover:
- Period it takes to perform post deployment test for defined use cases
- Period it takes to perform initial check should there be any issue occurred
Mostly we implemented 30–45 minutes post deployment maximum. This can be extended upon request to Release Manager stand by during deployment subject to error type. Should the error occurred consistently, and error rate increment immediately detect, RM will send rollback instruction after providing small amount of time window to collect error log and test evidence for further troubleshoot and root cause investigation after rollback completed.
Design Daily Deployment Sequence that Minimize Workaround, Troubleshoot and Enable Team to Isolate Error Fast.
As we have lots of service dependencies, we need to design deployment execution that avoid workaround to troubleshoot or error findings. We hadn’t applied tracer; hence it was not recommended to execute deployment of services that have dependencies at the similar period as it will take time to separate error root cause. Critical rule in daily basis that we apply:
- Don’t deploy in multiple gateway that have impact to same interfaces at the same time or short period amount of gap.
- Don’t deploy in services with overlap use cases at the same time or short buffer amount of time. Example: If you would like to deploy changes in service of OTP generator and OTP distributor to users, don’t do it at the same time, as should there be any findings on post deployment test, you will not be able to know immediately which services that caused the issues whether the failure in OTP generator, or it successfully generated but not successfully distributed. No matter how fast it is to check log in validating source of error, best to avoid investigation at all.
- Manage other require downtime activities and review how it will cause impact to relevant use cases. Decrease release frequencies if needed. This applied to other production activities that might have affect existing use cases such as migration, infra maintenance that require downtime, etc.
Measure What Matters. Define items to be measured and am not talking about trend in release/deployment metrics, only build the fundamental strong enough based on variables that we can immediately use to iteratively improve. Our options went to what type of changes being deployed (new features/improvements/hotfix), measuring deployment success rate and how frequent we deployed. That’s it. Refer to statement provided in the beginning, not aiming for aggressive lead time to changes. We’d like to identify our rate in performing successful deployment, how many we retained, how many needs to rollback.
Below are illustration sample of deployment quantities report mapped by changes type and deployment success rate (using data dummy).
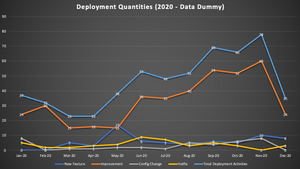
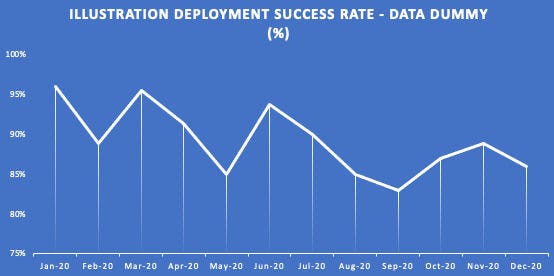
Of course, rollback measurement are arguable as factors could be vary, in order to avoid blaming we specifically categorized what are the main rollback reasons that will be measured:
- Miss out config and/or code
- Miss Dependency (infra not yet requested, relevant component set ups not yet completed example: topic Kafka creation, etc.)
- Miss out Support Changes in DB side (Missing script, etc.)
- Others/Undefine
Our main goal is to check how many of deployment failure that caused by bad planning and pre-execution check holes (category number 1–3).
Use Trend to Build Stakeholders’ Awareness and Improve Delivery. From time to time we can evaluate if the delivery process has been optimized and any process transformation will require support from stakeholders in enabling it. Hence, it is crucial to build stakeholders’ awareness to ensure we can have buy-in to support any improvement initiatives. We sent out some insights other than deployment frequencies report and success rate such as : Services with highest rollback contributor, and rollback composition based on defined category. This will trigger internal both awareness and urgency to act in improving the success rate or defined success criteria.
Illustration of failure rate insights and top rollback contributor (using data dummy)
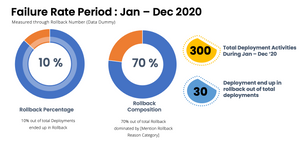
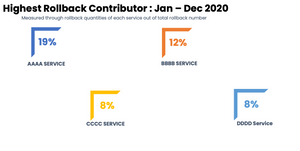
Takeaways
During the journey I found that other than prioritization focus on initial phase building deployment process from scratch where we decided to prioritize and solve visibility and observability on top of everything else (speed, automation, autonomy, etc.), the key is to consistently build discipline from time to time.
How?
- Stick to defined structured
- Create rules that allow behaviors shaping
- Design policy that will allow us to minimize deviations (situations where we needs to deliver outside of accepted rules)
- Educate stakeholders with Service Level Agreement that will ‘enforce’ to better planning
- Let the metrics guide you in revisiting potential improvement
We didn’t perform any tools or platform transformation during the past 2 years but managed to increase deployment success rate from 90% (2020) to ~96% (2021 per my departure), proof that operational discipline plays major part in deliveries success rate while aiming balance with system stability.
